


If your technology touches money, tracking funds is job number one. This is not a novel insight, as posts about bulletproof ledgers likely fill your LinkedIn feed. But is the financial industry dealing with an excess of accuracy?
Vague claims aren’t enough. That’s why we asked our lead platform architect, Emery Coxe, to walk through how we built our ledger from first principles. Along the way, we’ll share what other engineering teams should consider before building their own ledger.
Why we needed to build (or buy) a ledger
Under Treasury Regulation Section 1.408-2(e), entities that are not banks or insurance companies can request to be a nonbank trustee (NBT) for health savings accounts (HSAs). The IRS maintains a list of approved nonbank trustees who’ve demonstrated they’ve met the IRS requirements.
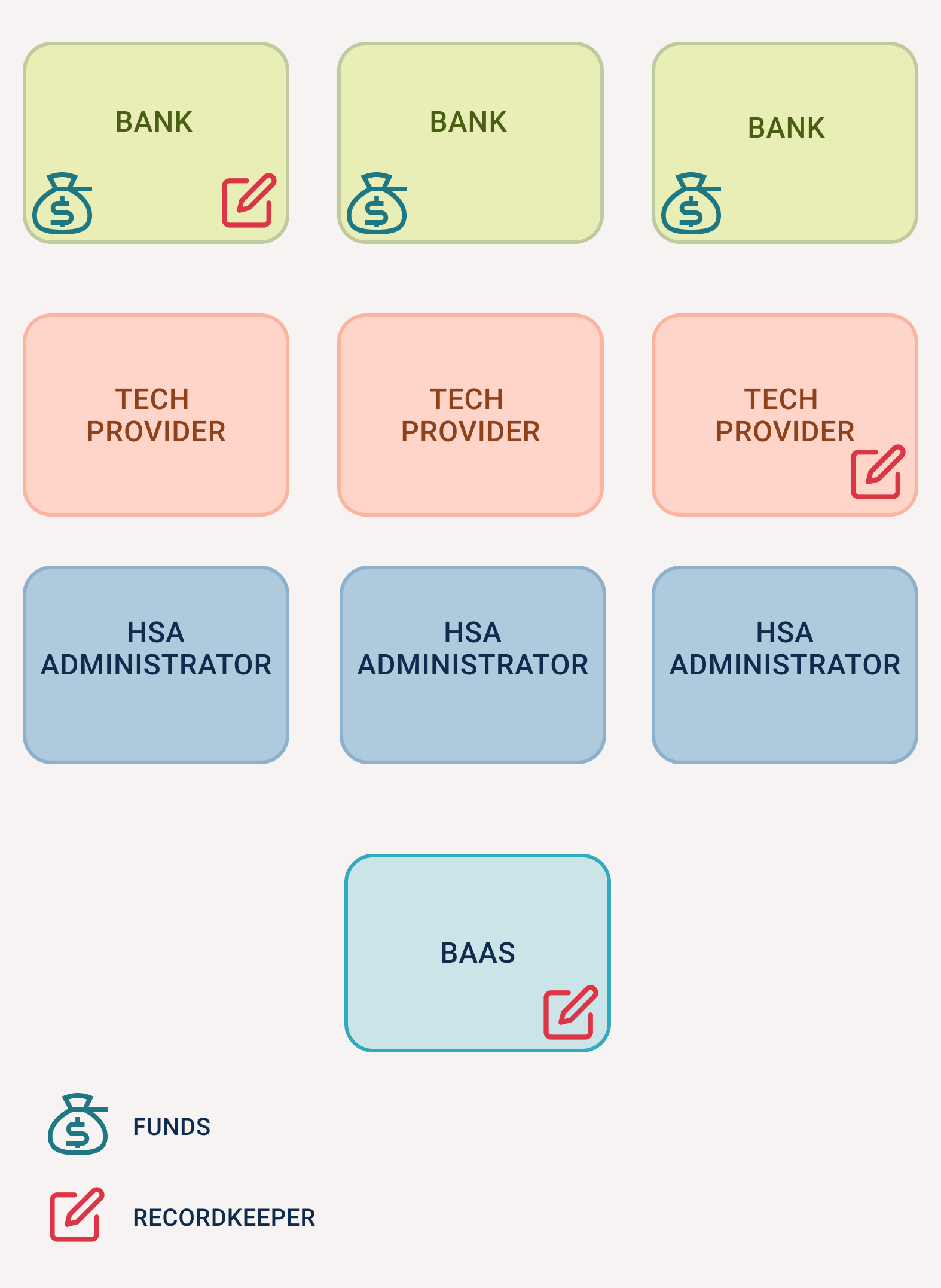
A company approved by the IRS to act as an NBT can act as the HSA recordkeeper—directly integrating with a bank’s core, owning ledgering, and generating all tax forms and account statements. As an approved NBT, we needed a ledger that gave us complete ownership of the system of record, immutable audit trails, accurate annual reporting, and rigorous asset safeguarding for regulatory compliance.
Building or buying a ledger
When considering our ledger solution, we arrived at our first question: Do we build, buy, or use an existing open-source solution?
Exploratory research
While time was limited, we recognized the critical nature of our choices and prioritized multiple weeks of exploratory research. We used an aggregate management approach, asking multiple team members to research and propose solutions to ensure we had a broad view of all possibilities. In addition to regular team discussions, each engineer used a Request For Comments (RFC) process to document their research and inform their recommendations.
Buy considerations
While some compelling options existed, we needed complete ownership and flexibility regarding the solution. Using a paid service for this data and system capability would have made First Dollar (and its customers) dependent on a third party, and ultimately, we wouldn't own the system of record and source of truth. From this lens, buying a ledger didn’t solve First Dollar’s fundamental problem.
Open-source evaluation
We evaluated a wide range of OSS projects. New entrant TigerBeetle stood out, but TigerBeetle did not recommend itself for production usage at the time; it would be worth considering today. Although we didn’t select any open-source solutions, we learned a lot from their implementation choices.
Planning for ledger development
Aligned with building our ledger solution, we arrived at our next set of questions:
- How do you build a ledger from first principles?
- What technologies will we use?
Selecting a technology
We could either use new technologies optimized for ledgers or build on our existing, conventional stack. (We use PostgreSQL as our general database solution for all problems, and implement application code in Typescript.)
As an engineering team, we aim to minimize complexity and surprise, and maximize simplicity and cohesion with existing systems and technologies. These principles and the Boring Technology principle led us to a simple conclusion: build First Dollar's ledger as an isolated, self-contained service using PostgreSQL and Typescript.
Building a ledger from first principles
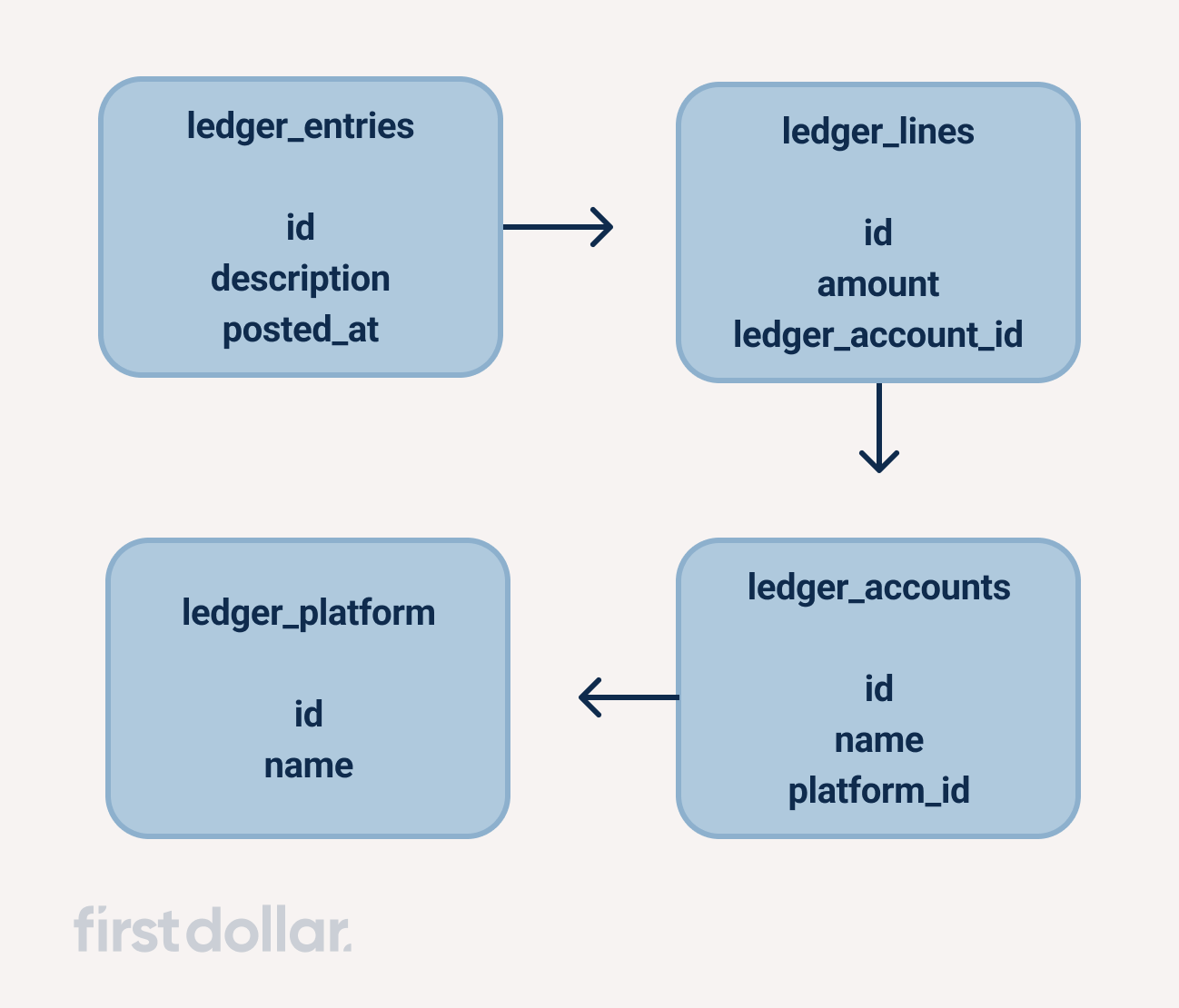
Having arrived at a set of technologies, we returned to the final question: How do you build a ledger from first principles? We approached the problem along the following lines:
- Define the domain model–the schema.
- Define the interactions between domain components–the API.
- Tie it all together via implementation.
Ledger schema
Let's start with the smallest building block.
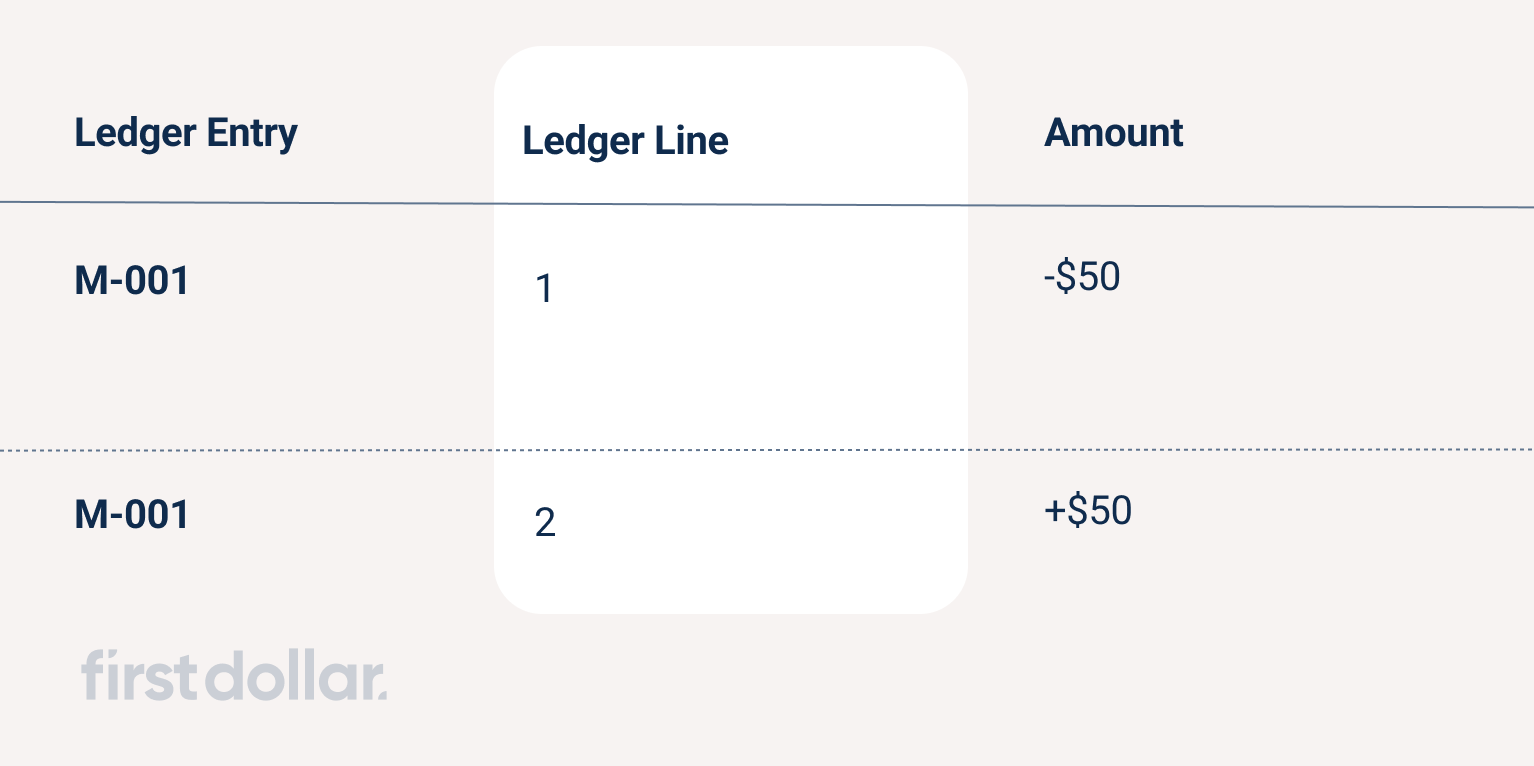
Ledger line
A ledger line represents a single debit or credit to a single ledger account in the scope of a single ledger entry. A single ledger account's history is the set of ledger lines across all ledger entries referencing the ledger account.
.png)
Ledger entry
A ledger entry represents a single event on a ledger platform. It is defined by two or more ledger lines, each paired against a unique ledger account, reflecting a state change to these accounts. Every ledger entry must satisfy all platform constraints, and most importantly, the conservation of value. In the scope of a single ledger entry, the sum of debits must equal the sum of credits.
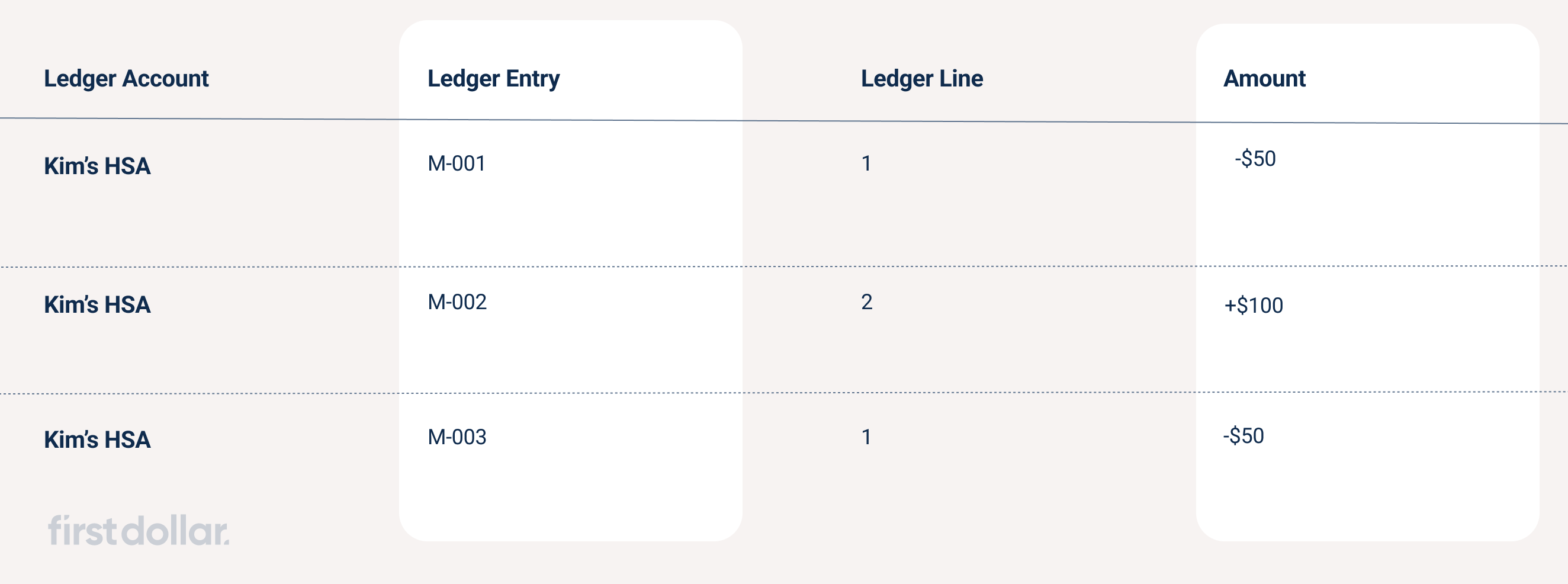
Ledger account
A ledger account is nothing more than a unique identifier—a way to tie a set of entries together. For convenience, we also assign a name attribute to each account. Entries relate actions between accounts on the same ledger platform.
Ledger platform
It's tempting to think of a ledger as one monolithic tool, but experience taught us it's better to model multiple distinct ledgers rather than a single shared one. We call this concept a "ledger platform"—a single ledger on which any number of accounts and entries can be created. A ledger entry can only interact with accounts on its own platform. This partitioning isolates accounts from unexpected actions and enables well-defined fund flows.
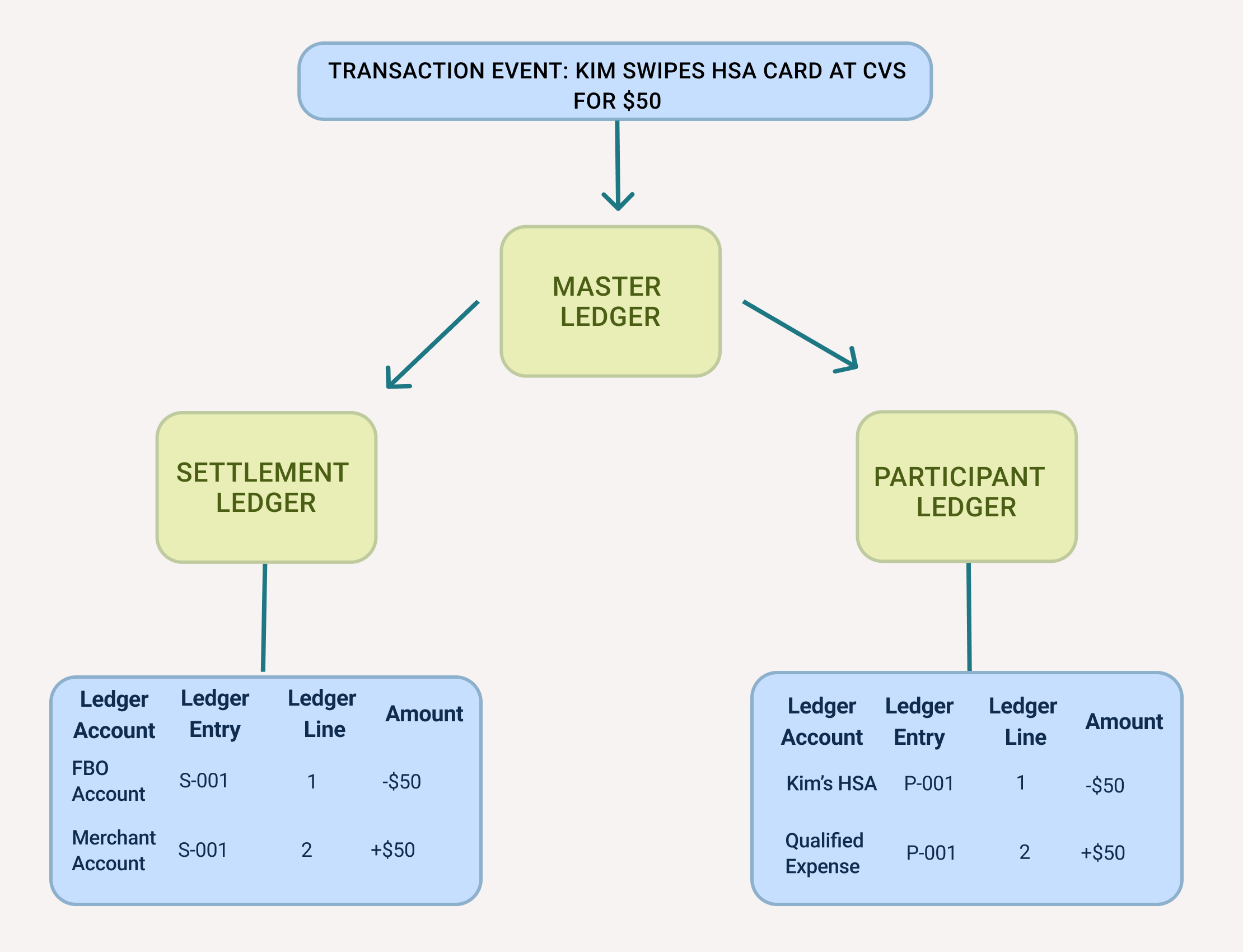
Ledger layer
A ledger layer separates entries into discrete states to more accurately represent the flow of funds. Layers are arbitrarily defined, but the First Dollar system uses two layers: pending and settled. The pending layer represents financial events that aren't yet complete (e.g., ACH holds and card pre-authorizations). The settled layer represents completed events; funds are available or spent based solely on this layer. Separating entries into layers enables richer balance calculations and better reflects the true state of funds throughout a transaction's lifecycle.

System constraints
The fundamental law of double-entry accounting: total debits equal total credits. Like the first law of thermodynamics, financial value is neither created nor destroyed – it’s conserved within a ledger entry. The entry is “balanced.” Edge cases arise from this law. Can one ledger entry have multiple debits and credits? Can those debits and credits be asymmetrical (e.g., one debit, ten credits)? Are $0 lines valid? Can an account receive a debit and a credit in the same entry? We prioritized simplicity and enforce these rules:
- An entry can have two or more lines; the number of debits and credits doesn't matter as long as they balance.
- $0 entries and $0 lines are not supported.
- An account can only appear once per entry—no mixing debits and credits for the same account.
Balanced entries
We can also apply ledger constraints at the database level. The “balanced entry” constraint – the fundamental law of double-entry accounting — is well suited for this. A PostgreSQL trigger maintains this data integrity.

Immutability
Ledger entries should be immutable—once recorded, never changed. In SQL, we achieve this by revoking DELETE and UPDATE permissions on the ledger tables.

Ledger API
We focused on simplicity and defined the narrowest possible API. Writing to the ledger happens through a single API – postLedgerEntry. createAccount is a necessary precondition to post entries. The two core read APIs follow.
Write
- createLedgerAccount
- postLedgerEntry
Read
- listLedgerEntriesForAccount
- getLedgerAccountBalances
Post ledger entry
The central operation of a ledger is the ability to record transactions between accounts. We call this a ledger entry and call this the `postLedgerEntry` API.

To post a ledger entry, we need to know the type and state of the transaction, the accounts involved in the transaction, the amounts for each account, the instant the transaction occurred, and a free- text description of the transaction.
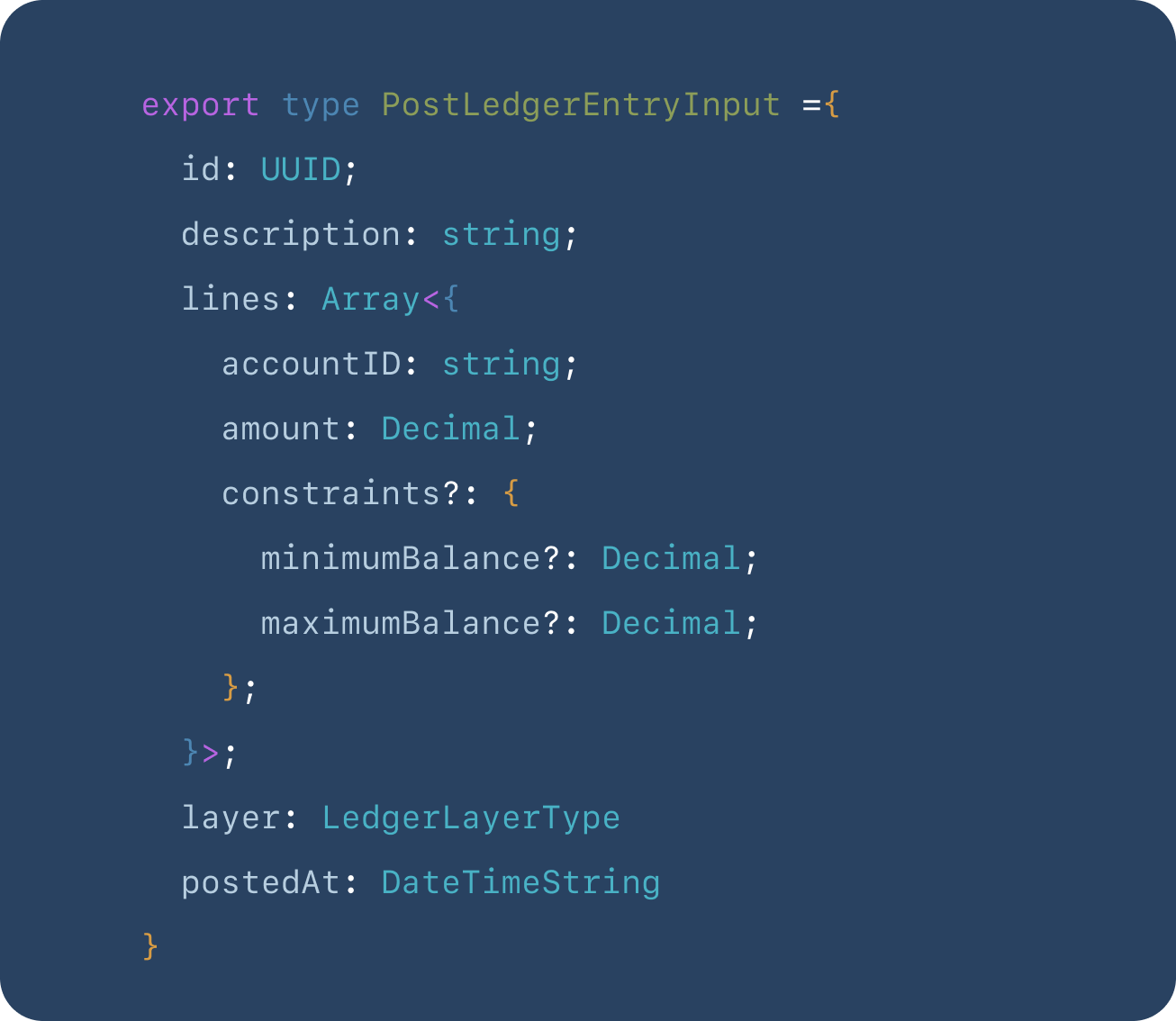
The operation is as follows:
- Validate the data.
- Check ledger entry preconditions.
- Write the entry.

Input and precondition validation was alluded to earlier and is omitted for brevity. We care about the heart of the operation here – the core data model.
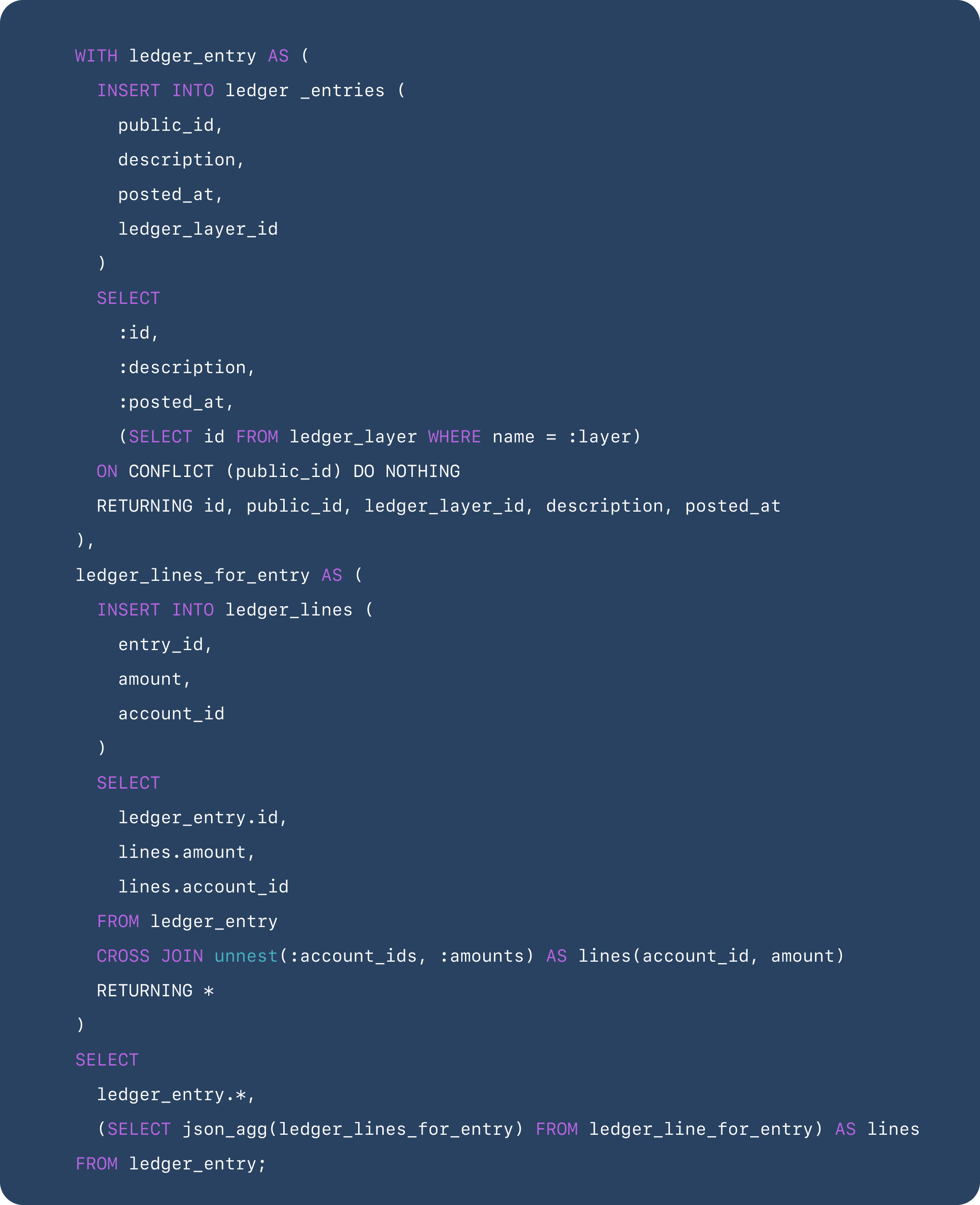
Within a single statement – or transaction – we insert the `ledger_entry` row and insert each line for the entry. Preconditions are validated at the application layer, and our trigger on `ledger_lines` ensures that the sum of all lines is balanced. With this implementation, we write entries to our ledger arbitrarily.
List ledger entries for account
Writing to the ledger is important, but we also need the ability to read the state of our ledger. The most common access pattern is viewing a single account's state, which is the set of entries with a line referencing that account.

For performance, we’ll require callers to access a page of entries at a time (e.g., last 100 entries). From the relational properties of our schema, the set of entries for a given account are the ledger entries where one of the ledger lines references the account in question. The SQL statement for this view is as follows.
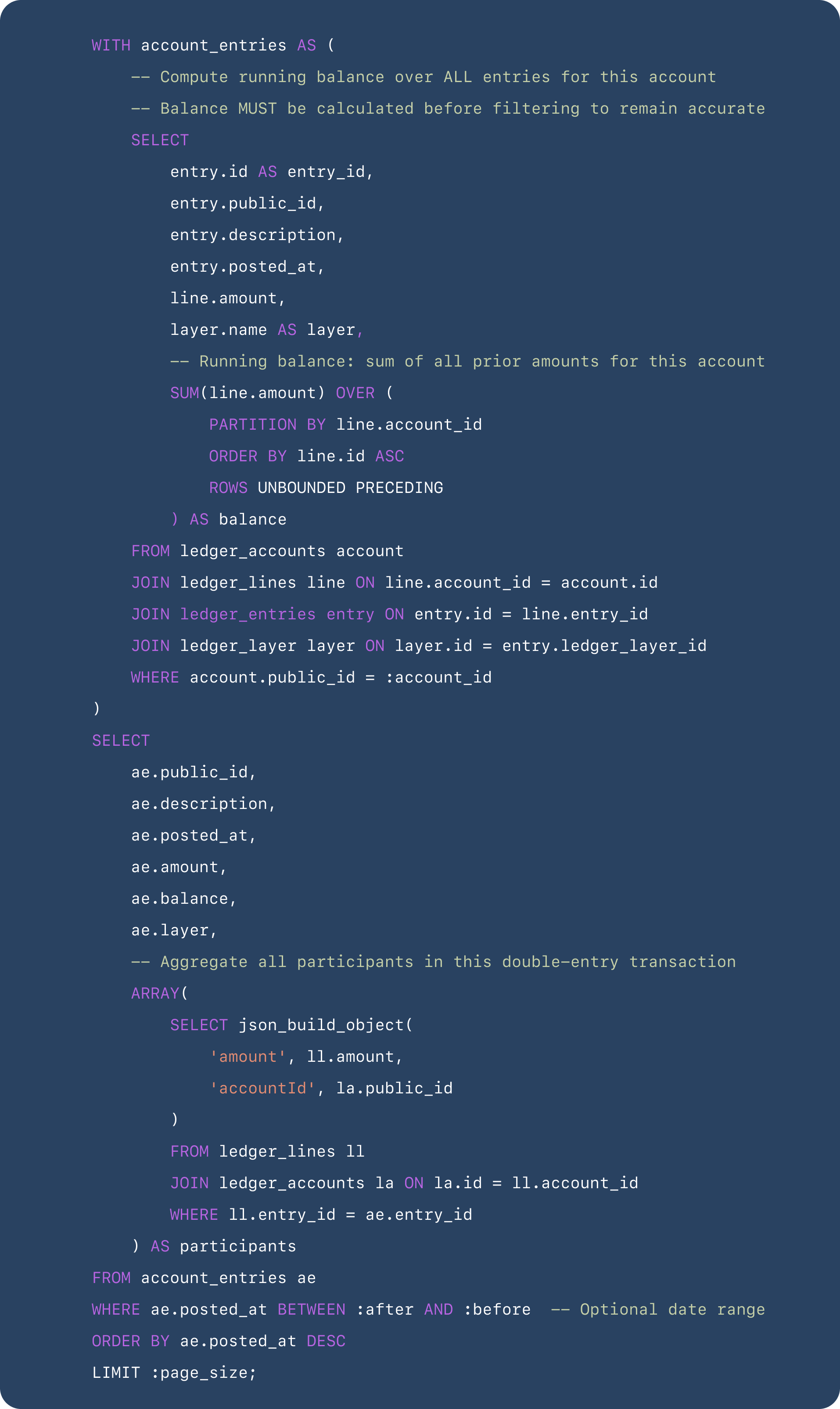
Let’s break this down. We select all entries with a line assigned to the requested account, compute balance for each line, and then apply paging, filters, and view logic to reflect all participants in a multi-line entry. The simple schema sketched out in this post doesn’t cache point-in-time balance. The sum of all lines for an account up to a point in time defines the balance of the ledger account at that instant. Thus, to calculate balance for each ledger line, we select all lines for the account and take the sum of the current line plus all lines before it. We do this for each entry, yielding the point-in-time balance for the account for the noted entry.
With this query, we can now view the complete state of any account in this ledger implementation.
Get ledger account balances
Although we have the ability to view balance by way of the List Ledger Entries API – simply look at the balance on the most recent ledger entry for an account – it’s convenient and useful to have an API that just returns the balance, rather than a list of ledger entries.

A balance could be a single value – but in practice, we compute several statistics separated out by ledger layer and account for concepts like reversals to provide a more useful business view into the balance state of an account.
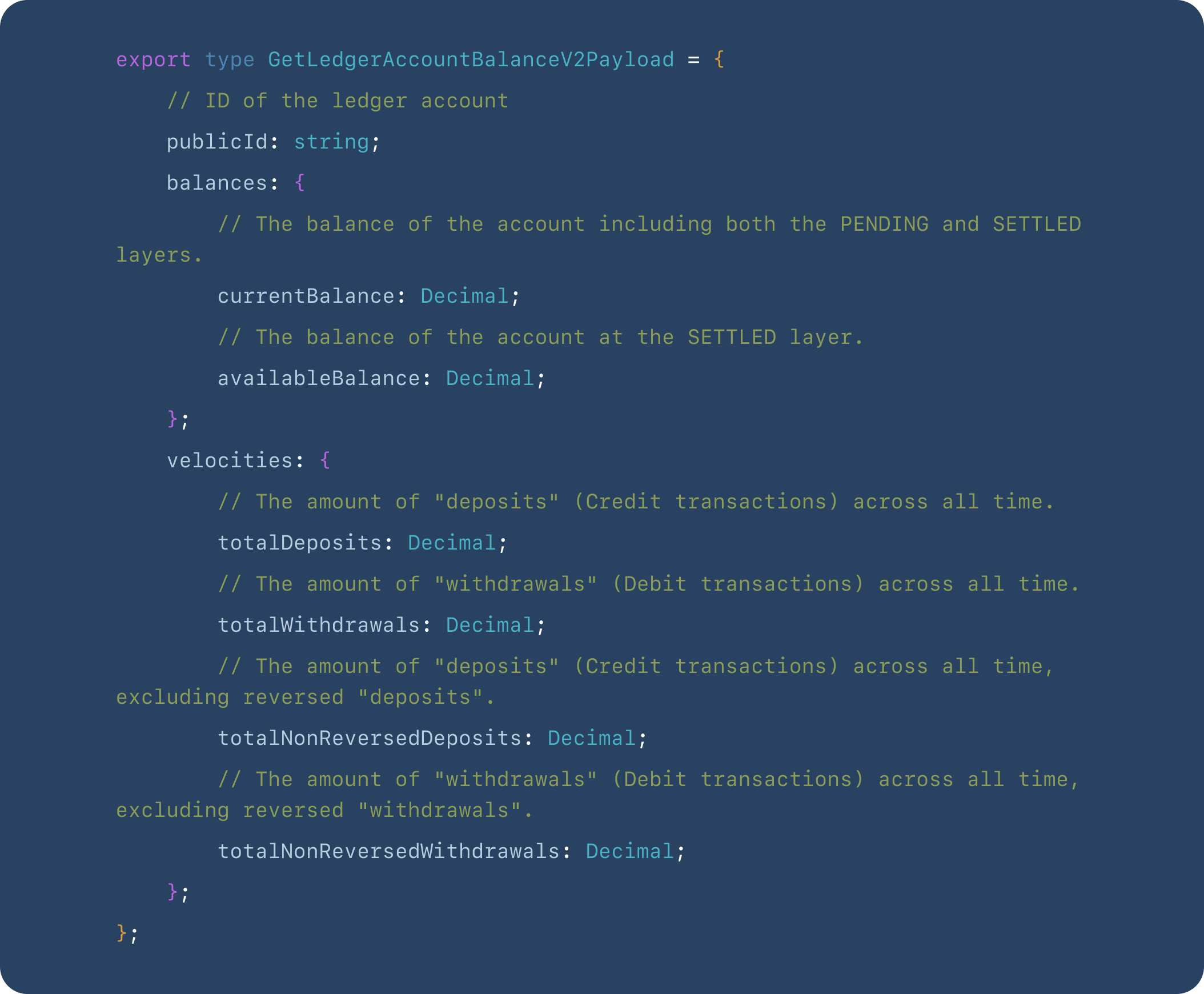
As before, since the ledger implementation discussed here doesn’t cache balances, we compute the balance the same as before: by summing all lines for a given account. In this case, select all lines for the account, then run various aggregates on them to produce the noted statistics.

A simpler implementation could simply sum all lines – without any of the constraints or filters we apply – and that would be valid, but with real- world usage, complexity would inevitably creep in, pushing the implementation towards something analogous to the above.
Convenience APIs
Using the primitives we developed above – `postLedgerEntry` in particular – we derive higher-level operations for convenience and correctness. A few such operations in our system include:
- `reverseLedgerEntry`
- `createHold`
- `promoteHold`
- `removeHold`
Advanced use-cases
The ledger described here is performant and scales beyond naive expectations. But it makes a tradeoff. Balance is calculated on every read. This scales beyond expectations, but for sufficiently large accounts – or for complex, multi-account queries – it breaks down. “Hot accounts” – ones that receive high volumes and high rates of entries – are fundamental to ledger implementations, and these accounts become bottlenecks that necessitate advanced techniques, including point-in-time balance caching.


.png)
